
Джастін Левандоскі, менеджер з розробки програмного забезпечення Google Cloud
Гаурав Саксена, старший менеджер із продуктів Google Cloud
Джерело: cloud.google.com
Обсяг цінних даних, якими організаціям доводиться керувати та аналізувати, зростає з неймовірною швидкістю. Ці дані все частіше розподіляються по багатьох місцях, включаючи сховища даних, озера даних та сховища NoSQL. У міру того, як дані організації стають все більш складними та розростаються в різних середовищах даних, виникають розрізнені сховища, що створює підвищений ризик та витрати, особливо коли ці дані необхідно переміщати. Наші клієнти чітко дали зрозуміти; їм потрібна допомога.
BigLake – це механізм зберігання, який дозволяє вам уніфікувати сховища та озера даних. BigLake дає командам можливість аналізувати дані, не турбуючись про базовий формат або систему зберігання, та усуває необхідність дублювати або переміщувати дані, знижуючи витрати та неефективність.
Завдяки BigLake користувачі отримують детальний контроль доступу, а також прискорення продуктивності в BigQuery та багатохмарних озерах даних AWS та Azure. BigLake також забезпечує єдиний та безпечний доступ до цих даних у Google Cloud та движках з відкритим вихідним кодом.
BigLake розширює десятиліття інновацій за допомогою BigQuery для озер даних у багатохмарних сховищах з відкритими форматами, щоб забезпечити уніфіковану, гнучку та економічну архітектуру озер.
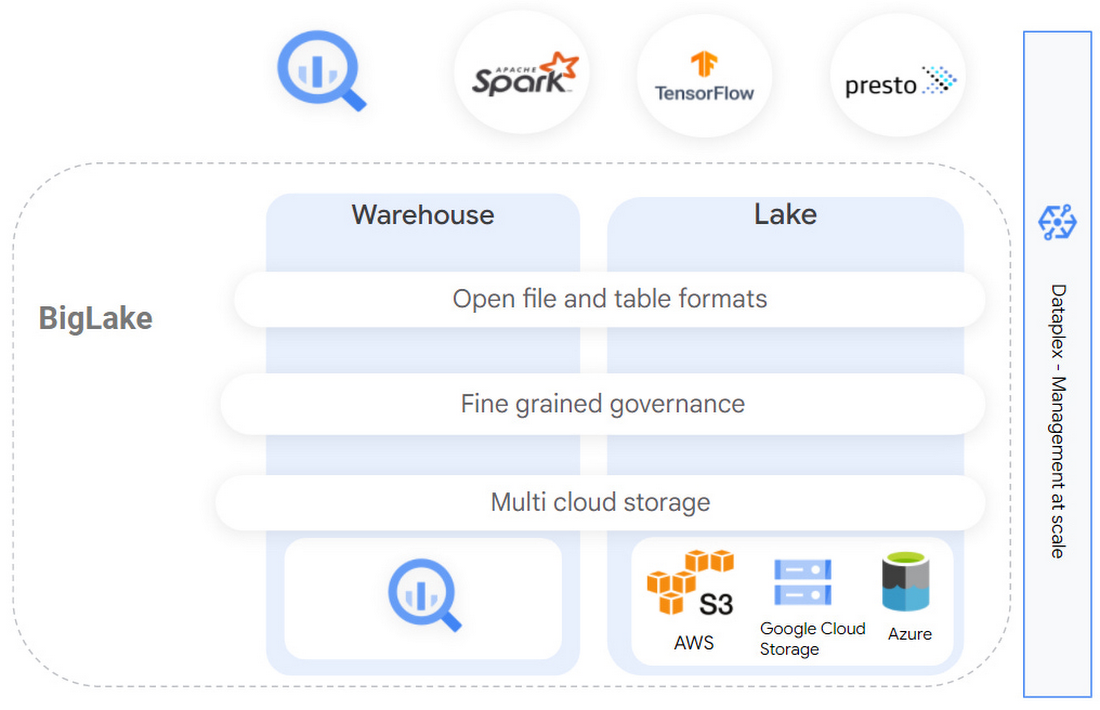
BigLake дозволяє:
- Поширювати BigQuery на багатохмарні озера даних та відкриті формати, такі як Parquet та ORC, за допомогою детальних елементів керування безпекою без необхідності налаштовувати нову інфраструктуру.
- Зберігати єдину копію даних та застосовувати узгоджений контроль доступу для вибраних вами аналітичних систем, включаючи Google Cloud та технології з відкритим вихідним кодом, такі як Spark, Presto, Trino та Tensorflow.
- Забезпечувати уніфіковане керівництво та управління в будь-якому масштабі завдяки безшовній інтеграції з Dataplex.
Bol.com, один із перших клієнтів, які використовують BigLake, прискорює отримання аналітичних результатів за збереження низьких витрат:
Як швидко зростаюча компанія електронної комерції, ми спостерігаємо швидке зростання даних. BigLake дозволяє нам розкривати цінність озер даних, забезпечуючи контроль доступу до наших представлень, поєднуючи в спільний інтерфейс та знижуючи витрати на зберігання даних. Це, своєю чергою, дозволяє нашим користувачам швидше аналізувати наші набори даних.
Мартін Цекодхіма, інженер-програміст, Bol.com
Розширте можливості BigQuery, щоб об’єднати сховища даних та озера з керуванням у мультихмарних середовищах.
Створюючи таблиці BigLake, клієнти BigQuery можуть розширити свої робочі навантаження на озера даних, створені на базі Google Cloud Storage (GCS), Amazon S3 та Azure Data Lake Storage 2-го покоління. Таблиці BigLake створюються з використанням підключення до хмарних ресурсів, що є оболонкою службової ідентифікації, яка забезпечує можливості управління. Це дозволяє адміністраторам контролювати доступ до цих таблиць аналогічно таблицям BigQuery і усуває необхідність надавати кінцевим користувачам доступ до сховища об’єктів.
Адміністратори даних можуть налаштувати безпеку на рівні таблиці, рядка або стовпця у таблицях BigLake, використовуючи теги політики. Для визначених у Google Cloud Storage таблиць BigLake постійно застосовується точне налаштування безпеки та підтримуються механізми з відкритим вихідним кодом, які використовують конектори BigLake. Для таблиць BigLake, визначених у Amazon S3 та Azure Data Lake Storage 2-го покоління, BigQuery Omni забезпечує керовану багатохмарну аналітику за рахунок застосування елементів керування безпекою. Це дозволяє вам керувати однією копією даних, що охоплює BigQuery та озера даних, та забезпечує взаємодію між сховищами даних, озером даних та сценаріями використання data science.

Відкритий інтерфейс для одноманітної роботи в аналітичних середовищах виконання, що охоплюють технології Google Cloud та механізми з відкритим вихідним кодом.
Клієнти, які використовують механізми з відкритим вихідним кодом, такі як Spark, Presto, Trino та Tensorflow, через Dataproc або самокеровані розгортання, тепер можуть включити детальний контроль доступу до озер даних та підвищити продуктивність своїх запитів. Це допомагає створювати безпечні та керовані озера даних та позбавляє необхідності створювати декілька представлень для обслуговування різних груп користувачів. Це можна зробити, створивши таблиці BigLake із підтримуваного механізму запитів, такого як Spark DDL, та використовуючи Dataplex для налаштування політик доступу. Потім ці політики доступу послідовно застосовуються у всіх механізмах запитів, які звертаються до цих даних, що спрощує управління контролем доступу.
Забезпечте уніфіковане управління в будь-якому масштабі за рахунок безшовної інтеграції з Dataplex.
BigLake інтегрується з Dataplex для надання можливостей масштабного управління. Клієнти можуть логічно організовувати дані з BigQuery та GCS в озера та зони, які зіставляються з їхніми доменами даних, та можуть централізовано керувати політиками управління цими даними. Потім ці політики одноманітно застосовуються механізмами запитів Google Cloud і OSS. Dataplex також спрощує керування, автоматично скануючи сховище Google Cloud для реєстрації визначень таблиць BigLake у BigQuery та роблячи їх доступними через Dataproc Metastore. Це допомагає кінцевим користувачам знаходити ці таблиці BigLake для вивчення та виконання запитів за допомогою як програм OSS, так і BigQuery.